DATA 310 MACHINE LEARNING - 07/14/2020
1.)
When using a convolution, it gives the algorithm the ability to better perform using its neural networks. Incorporating the convolution also gives your algorithm the ability to stop overfitting or underfitting your model comapared to previous posted code. Within the convolution itself, as the picture is turned to black and white, each pixel within the image is given a number designated by how saturated or unsatured it is. For example, if you have a smaller number, the lighter it is. Once the picture has been changed, a filter is applied and to the image, which is smaller than the original image, and is extended to each individual pixel in the image itself. Once the image has been ran through the filter the image, orginally 3x3, will come out smaller, 2x2. Depending on your value in the filters the values should be equal to 0 or 1, if they are not equal to 0 or 1, then a weight should be added so that the values will reduce or increase to the desired 0 or 1. Extending over each individual pixel in the photos, the filter emphasizes certain aspects of the image depending on your photo as you will see in the following examples.


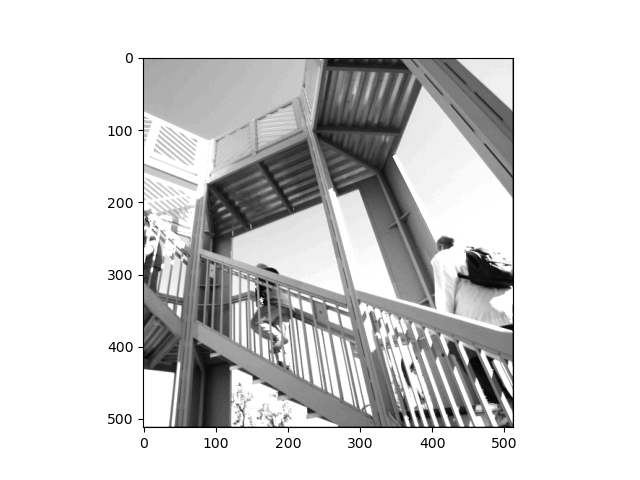
Above, the filter that has been applied is [-3, 6, -2], [1,-2,1], [0, -1, 0]. As seen, the image has been changed to black and white and the saturation is higher. You can also see that many of the vertical lines have been highlighted and displayed in the image.
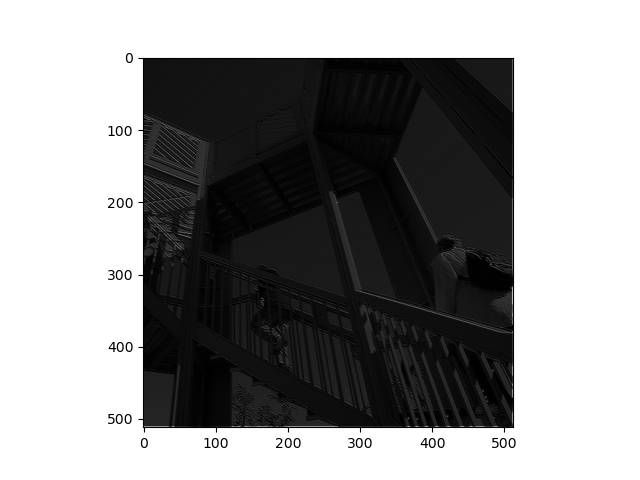
In this filtered image, we use [1, -2, 1], [3, -3, 1], [-1, 2, -1]. In this photo, an eclipse effect seems to come over the image and the only pieces that are slightly highlighted is the railing in the top left part of the image.
Unlike the other images, this one uses slightly configuration with a weight of .2 instead of the usual (1, 0, .1). [-1, 0, 1], [4, 0, 4], [-2, 0, 4]. In this image, you can see that it has been enhanced and is unsaturated compared to the other photos above.
2.)
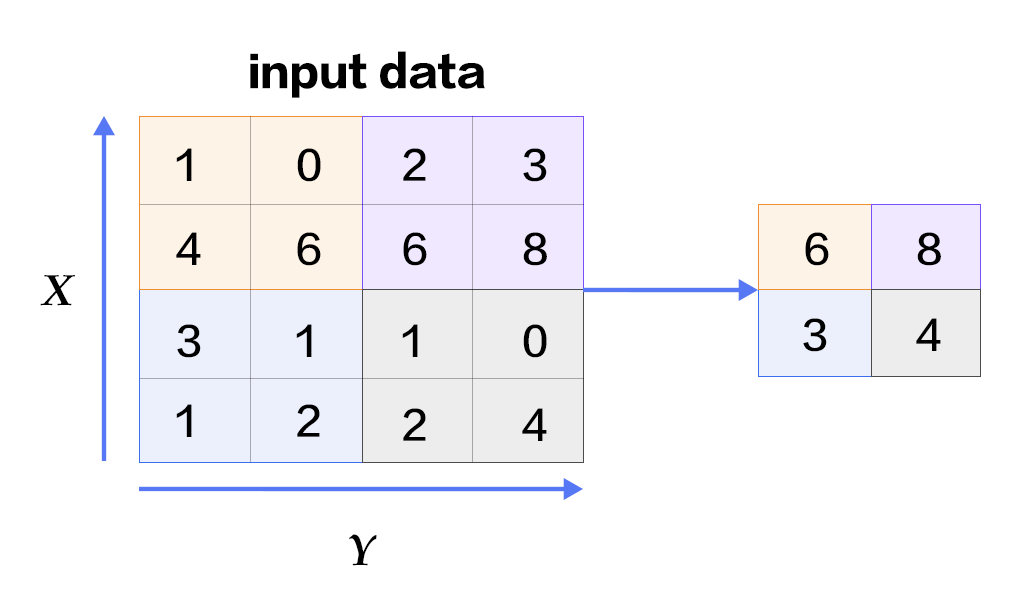
Unlike using the convolution function above, pooling instead tends to downscale an image that is obtained from previous layers. In other words, it is compared to shrinking an image in order to reduce its pixel density. The most common type of pooling is Max Pooling. Max Pooling, for example, is if you were to buy a new scale model Ford GT-40 which is about, lets say a 2x2 compared to the real car which is 4x4. When the model is reduced though it needs to still hold the figure of the original and detail. Though the car is not 100% the same as its original, it still holds some of the value, important data in the case of images, as the original full-scale. Though I configured my code to import, read, and filter the picture of an actual Ford GT40, the pooliing module did not feel like cooperating. I will post my code in the second half of my entry in the private repository.

In this sample of pooling, you can see the distorsion in the photo as it is shrinking. It also brings emphasis on layers that have a larger light path hitting them. The filter used for this was [3, 0, -3], [-2, 0, 2], [-1, 0, 1].

For this image, the distorsion and shrinkage is slightly (very slight) less but it with the filter used, it seems more like the algorithm had reduced the light but also added a tracing factor into some of the vertical, horizonal, and angled lines along the staircase and upper deck. The filter used for this is [0, 1, 0], [1, -4, 1], [0, 1, 0].

Lastly, this image shows an a larger amount of distorsion after it had been reduced. The image also shows highlights in the lighter parts of the upper decking, people, and lower railing. The filter used for this is [5, 1, -6], [-1, 2, -1], [-2, 4, -2].
3.)
Compared to the DNN, CNN seems like the more plausible option in terms of Neural Networks. Within the first epoch, the CNN was already at 0.9875 accuracy with 0.0398 loss, while the DNN ended the last epoch at 0.9735.
DNN: Accuracy: 0.9735 - Loss: 0.0721
CNN: Accuracy: 0.9978 - Loss: 0.0302
According to the above figures, CNN is clearly the better model and although it takes about 10 minutes more to run, it is worth it.
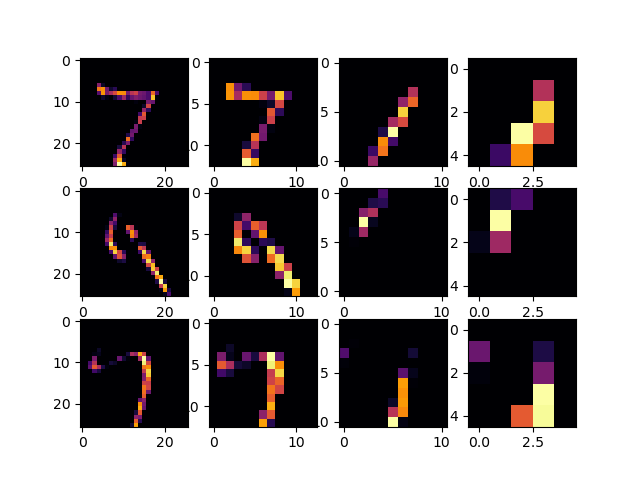
I found that when I changed my CONV2D from 64 to 32 the images seemed to be more clear and performed better with an overall accuracy of 0.9904 compared to both the 64 and 16 inputs. The more convolution layers that are added the more the image pixels are shown and the clearer they become.